9. Project Challenges¶
So, did you think your first big project was going to finish that easily? Ha ha hah not so fast, ho’mes . In this chapter we’ll explore the numerous details that can, and almost certainly will go wrong. That is, if the project team is not aware of and vigilant in avoiding these common mistakes.
Now that computer hardware and software tools have caught up to engineers and are no longer a great burden to use, the remaining issues and ID10T errors are caused largely by touchy bags of meat at the controls.

Might you be aware dear reader, that most of the organizational challenges your project is facing today were recognized, managed, and written about by the freakin’ 1970s!? It’s a recurring theme of this chapter, regrettably. If only there were some resources to help with these issues—oh, wait.
See also: Books
The Mythical Man-Month: Essays on Software Engineering, 2nd Edition, Frederick P. Brooks, Jr.
It’s hard to read it without saying “Right on!”
every couple of pages.
— Steve McConnell, Code Complete (Ch. 28)
Large scale software project management hasn’t changed much since the early days of computing. Why? Because while computers may change, people haven’t. This is the classic book that PM and developer alike should read. Its warning about adding people to a late project, aka Brooks’ Law, is now well-known, but it is chock-full of additional insights and history. This new anniversary edition has been recently updated with lessons learned and also includes the famous silver-bullet essay.
Tip
Refer to this chapter and the section(s) on cost containment under quality for discussion points when inexperienced clients or managers claim best-practice is too costly.
9.1. Risk¶
If you don't actively attack the risks [in your project], they will actively attack you.
— Tom Gilb
Dictionary.com defines risk as “exposure to the chance of injury or loss; a hazard or dangerous chance.” Risk is uncertainty; a potential problem that may manifest itself later as an actual problem. While we discussed risks and Risk Management briefly from the Software Quality angle, there is quite a bit more to cover from a project management perspective.
Known Knowns
Below is an insight imparted by the controversial Donald Rumsfeld on classifying risks, the emergent properties of project management, and their predictability :
As we know, there are known knowns.
There are things… we know we know.We also know there are known unknowns.
That is to say, we know there are some things we do not know.But there are also unknown unknowns,
the ones we don’t know, we don’t know.
That helps us classify project risks pretty well, no? Applied to our discussion, we have:
Known-knowns: these are our project scope and requirements.
Known-unknowns: recognized risks to the project.
Unknown-unknowns: where we get blind-sided.
We cannot fully prepare for these risks ahead of time, except perhaps to create a contingency fund beforehand and reconcile them as soon as is practical.
There’s been a recent addition to this talk with another case:
Unknown-knowns: bad assumptions, the things you think you know, that it turns out you did not . (Blind-sided indeed)
9.1.1. Risk Management¶
Risk management is a integral part of software engineering project management because so much of what goes on during software development is uncertain and non-deterministic.
— Eddie Burris, UMKC Software Engineering Dept.
Risk management consists of these steps:
|
|
Imagine your project is a ship heading off into the night through a heavily mined body of water. Risk management is the act of searching for potential project-sinking problems, and steering around them before they do damage:

Identification
A project review should be performed (think code review) during the kickoff meeting to identify and classify risks. SWOT (Strengths, weaknesses, opportunities, and threats) and root-cause analysis are two popular methods of risk identification. Typical risks include:
Loss of resources, such as personnel or hardware.
Scope Creep (discussed below)
Changes in direction and/or leadership
Redesign, rework, and/or major bugs affecting timeline
(see: unpredictability of time to fix)Issues with outsourced components
New platforms or languages to ramp up on.
Our own failure, gulp.
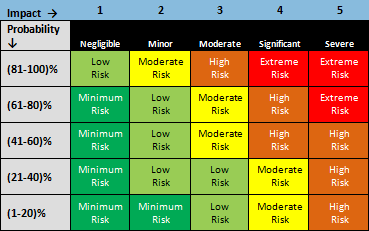
Analysis and Prioritization
Once the risks are gathered, creation of a risk matrix for analysis is appropriate for sizable projects. This is easily done in a spreadsheet—simply multiply potential impact with the probability the risk will occur, with a bit of color assigned to results.
Response Planning
The real reason for risk management:
It’s not to make the risks go away, but to enable sensible mitigation should they occur. And mitigation may well have to be planned and provisioned well ahead of time.
— DeMarco/Lister, Peopleware (Ch. 30), "Dancing with Risk"
Once analyzed, it is time to devise ways how to prevent, avoid, and mitigate these potential problems. Keep your organization’s policies, strategy, and level of tolerance close at hand when making plans.
There are two kinds of risk response plans, action plans for avoiding or reducing risks, and contingency plans for responding to risks that do become problems. Risk response plans may employ one or more of the following strategies roughly in order:
- Risk Avoidance:
Choose a safer alternative.
Can’t avoid the risk? Continue on to other techniques below.- Risk Transfer:
Pay someone else to assume the consequences, e.g. insurance.
Can’t transfer it?- Risk Mitigation:
Reduce the probability and/or impact of a risk.
Can’t mitigate it?- Risk Acceptance:
May be the only option when treatment isn’t cost effective.
Secondary risks—those that may happen in reaction to your response—should be noted as well. Say for example development of the project’s external website has been outsourced. With ship-date looming it arrives late and the work is decidedly amateur. Someone “knows a gal” but she’s booked for two-weeks solid on a higher-paying gig. Your own team is already in “crunch-mode.” It happens (and in waves), plan ahead. Have a “Plan C” for ultra-critical tasks.
When risks do turn into problems the time comes to shift into crisis management or “fire fighting” mode, executing prepared contingency plans.
9.1.2. Scope Creep¶
…perfection is attained not when there is nothing more to add, but when there is nothing left to remove.
— Antoine de Saint-Exupéry, "Terre des Hommes"
It’s common for clients to have a reasonably firm idea of how much they can
afford and how long a project should take,
often leaving scope (what to do) the most flexible constraint.
As a result,
one of the most persistent threats
to the health of any project is “scope creep”,
aka “feature creep”—which is
a substantial expansion in the number of planned features as it proceeds.
Simply put,
it’s the tendency for all involved to think,
“Hey, why don’t we add $GREAT_FEATURE!”
You’ll need to be vigilant in combating it,
as the urge to get “just a few little things” in is powerful.
The video clip above is from “Pentagon Wars” , a darkly funny dramatization of scope creep on large projects that should prompt every taxpayer to shed a tear or two. You may need to watch it twice to catch all the details.
Keeping with the government theme, an unfortunate real-life example was the design of the Space Shuttle . Driven sadly off-course by political concerns, scope creep (to meet unused military requirements) resulted in missed economic goals (too big and costly) and an increased failure rate (it tended to blow up).
Don’t let scope creep doom your project—chances are high you won’t be promoted, as satirized in the piece above. :-(
Classifying Feature Requests
There are (at least) two kinds of feature requests that need to be considered, the essential, and the nonessential. How to decide between the two will be unique to each project. For example, an obligatory case may have been forgotten during the requirements phase or emerged spontaneously. Such essential features will need to be negotiated, estimated, approved, and the project re-scheduled. Late feature additions should be managed through the aforementioned change control board (CCB).
Saying “no” to the other nonessential requests will be difficult at times, but must be done to maintain the health of the project.
Under-Promise and Over-Deliver?
The project should deliver exactly what the customer expects. No more, no less.
— Luckey/Phillips, Software Project Management for Dummies
While as a goal it sounds admirable to over-deliver, it turns out that efforts to deliver more than the client expects can backfire. A few reasons to avoid over-delivering are described below, courtesy “Software Project Management for Dummies” :
The client may believe the project could be delivered faster and cheaper than it did due to the inclusion of extras it didn’t ask for.
Bugs may occur in the extra features, increasing risk.
The client may not want the extra features for reasons unknown to developers, such as policy or byzantine industry regulation.
Tip
If you are motivated to excel and over-deliver, direct the energy into finishing early instead.
See also: Online Resources
Taming the Scope Creep, courtesy Team Gantt.
Five steps to prevent Scope Creep, courtesy of Bidsketch :
Understand what your client wants to achieve.
Collaborate with your client to produce a solution.
Define the scope of work that will provide that solution.
Price the solution in a manner that reduces the likelihood of expansion, by charging for it.
Agree to the details of the service delivery in writing.
9.1.3. Second System Effect¶
The second is the most dangerous system a person ever designs; the general tendency is to over-design it.
— Frederick P. Brooks, Jr., The Mythical Man-Month (Ch. 5)
Or syndrome as it may be called, notes the tendency for the second system (aka completed project) built by a team to greatly expand in feature set over the first. The expansion in scope is often enough to threaten the project, as it grows into a “feature-laden monstrosity.” Many experienced developers are caught unaware.
First described in the Mythical Man-Month, Brooks’ contrasts the simple IBM 70XX series operating systems to the featureful OS/360, which was a “second system” for most of the architects :
An architect’s first work is apt to be spare and clean. He knows he doesn’t know what he’s doing, so he does it carefully and with great restraint.
As he designs the first work, frill after frill and embellishment after embellishment occur to him. These get stored away to be used “next time.” Sooner or later the first system is finished, and the architect, with firm confidence and a demonstrated mastery of that class of systems, is ready to build a second system.
This second is the most dangerous system a man ever designs. When he does his third and later ones, his prior experiences will confirm each other as to the general characteristics of such systems, and their differences will identify those parts… that are particular and not generalizable.
Brooks makes another point related to second-systems, that there’s a tendency to “refine techniques whose very existence has been made obsolete by changes in basic assumptions.” He describes newly improved (yet obsolete) components such as the linkage-editor and batch (non-interactive) debugger as the “last and finest of the dinosaurs”—improvements completed that no longer made much sense.
Tip: Speak Up
Be aware of the tendency to over-design second systems, exercise additional self-discipline, and be prepared to raise the subject on overly-ambitious projects that need focus.
9.1.4. Full Rewrites Considered Harmful¶
…when you start from scratch there is no reason to believe that you are going to do a better job than you did the first time.
— Joel Spolsky, "Things You Should Never Do, Part I"
More specifically, full from-scratch rewrites of large-scale commercial applications. You may remember back when Netscape open-sourced their Communicator suite at the turn of the century. *cough* They decided to write a brand-new “second system” named the Mozilla Suite. (Apparently unbeknownst to them Brooks’ MMM anniversary edition was published in 1995.) It would fix everything that plagued Communicator.
While understandable given Communicator’s problematic history and technical debt, that was a tall order in itself. But, then they decided to attempt another huge project, the creation of a cross-platform GUI toolkit called XUL to write it in. Despite the ignorance of youth, this author thought at the time, “what in the hell… are they thinking?” Qt and WxWidgets (among others) were mature at that point. It was damn risky and unnecessary for an application developer to reinvent GUI programming in addition to a ground-up rewrite of a remarkably large and featureful browser, editor, and mail client.
That decision would have killed almost any other project, and given its size, many companies. As you may know it survived. Saved by two things:
Its open-source nature reduced costs and made deadlines less important.
More importantly their competitor Microsoft, uncharacteristically and unbelievably? declared victory and walked away for over five years (2001 - 2006 ). A one-in-a-million lucky break.
“Dangerous Folly”
Joel Spolsky goes even farther to discourage from-scratch rewrites in his now classic post, “Things you should never do, (Part I)” :
Three years is an awfully long time in the Internet world. During this time, Netscape sat by, helplessly, as their market share plummeted.
It’s a bit smarmy of me to criticize them for waiting so long between releases. They didn’t do it on purpose, now, did they? Well, yes. They did. They did it by making the single worst strategic mistake that any software company can make: They decided to rewrite the code from scratch.
Simply put, if your team “goes away” for three years to do a full rewrite rather than incremental improvement, competitors will eat your lunch. If you’re building something smaller, not dependent on commercial success, you may “plan to throw one away,” , but it must be done early not ~eight years into the project.
9.2. Late Delivery¶
I don't feel tardy…
— Van Halen, "Hot for Teacher"

Fig. 9.4 J.I.T. Delivery. ¶
The dismal reality of medium to large project estimation, courtesy Steve McConnell, Rapid Development:
The development-time problem is pervasive. Several surveys have found that about two-thirds of all projects substantially overrun their estimates (Lederer and Prasad 1992, Gibbs 1994, Standish Group 1994). The average large project misses its planned delivery date by 25 to 50 percent, and the size of the average schedule slip increases with the size of the project (Jones 1994). Year after year, development-speed issues have appeared at the tops of lists of the most critical issues facing the software-development community (Symons 1991).
Why do software projects routinely run late? A number of reasons for this have been identified, a few of which are detailed below:
- Planning Fallacy:
- The first 90 percent of the code accounts for the first 90 percent of the development time. The remaining 10 percent of the code accounts for the other 90 percent of the development time.
— Tom Cargill, Bell Labs One of the realities of technology and life is that things are constantly going wrong (in the small if not the large). We tend to push these hurdles out of our heads as soon as each is passed, because who wants to waste another second dwelling on the minor annoyances of life? When it comes time to estimate tasks, we’re blissfully unaware of these chronic micro-obstructions. Because of this, planners tend to focus on optimistic rather than actual scenarios :
In a 1994 study, 37 psychology students were asked to estimate how long it would take to finish their senior theses. The average estimate was 33.9 days. They also estimated how long it would take “if everything went as well as it possibly could” (averaging 27.4 days) and “if everything went as poorly as it possibly could” (averaging 48.6 days). The average actual completion time was 55.5 days, with only about 30% of the students completing their thesis in the amount of time they predicted.
- Optimism Bias:
- …an unvoiced assumption which is quite untrue, i.e. that all will go well.
— Frederick P. Brooks, Jr., The Mythical Man-Month (Ch. 2)The tendency to believe we are luckier than others, and/or “above average.”
- Self-serving Bias:
We tend to credit ourselves for things that go well, but blame delays on outside influences, leaving us to underestimate time to completion.
Innovation Risk
Because the programmer builds with pure thought-stuff, we expect few difficulties in implementation.
— Frederick P. Brooks, Jr., The Mythical Man-Month (Ch. 2)
“Show me.”
There are also non-psychological reasons for the difficulty of estimation that have to do with the nature of software and innovation itself. When developing, we (smartly) reuse code for mundane tasks as often as possible. As a result, most of the remaining work is in the research and development of unique or innovative technology and acquisition of new skills. This makes accurate estimation very difficult. For example, how long would it take you to earn a red belt in Kung-Fu and come up with several unique moves? (Outside of the Matrix, of course). “Fuck if I know,” is a rational answer.
9.2.1. Capped Upside vs. Unlimited Downside¶
As humans, we are always hopeful that the task that finish below the median time will “make up” for the tasks that go over. But while there’s a lower bound to how “under” the median a step can be—a step can’t take negative time—there’s virtually no upper limit to how much over a task can take.
— Priceonomics, "Why Are Projects Always Behind Schedule?"
Priceonomics explored the question in their article, “Why Are Projects Always Behind Schedule?” and generated a number of good comments on Hacker News . Tasks can never be done faster than immediately, but potentially may take up to “forever.” Therefore, those tasks that finish ahead of schedule have a limited potential to balance out those running behind.
Another aspect of the problem is that any hard-won extra time often goes unused. When one is ahead of schedule, its not uncommon to relax a bit and catch up with the ol’ inbox, right? And occasionally, moving forward earlier is simply not possible:
In addition to that, a project's ahead-of-schedule deliveries are typically wasted, but behind-schedule deliveries accumulate.
As an example: Arriving to the airport an hour in advance doesn't allow you to actually board an hour earlier. But, get to the airport one hour late — and you're flying tomorrow (or whenever the next flight is scheduled).
— kirushik on HN
Number of Milestones
A large programming effort however, consists of many tasks, some chained end-to-end. The probability that each will go well becomes vanishingly small.
— Frederick P. Brooks, Jr., The Mythical Man-Month (Ch. 2)
As the priceonomics article also describes, the greater the number of steps in a project, the less likely it will finish on schedule due to delays accumulating faster than advances.
9.2.2. Brooks’ Law¶
Adding "manpower" to a late project makes it later.
When schedule slippage is recognized, the natural (and traditional) response is to add manpower. Like dowsing a fire with gasoline, this makes matters worse.
— Frederick P. Brooks, Jr., The Mythical Man-Month (Ch. 2)
The law, described by Brooks as “an oversimplification that holds true in general,” is that adding people to a late project slows it even further. During the OS/360 project documented in the book, it was found that the new folks needed time to “ramp up” with training before becoming productive, requiring communication from others. These factors slowed down the already productive. The “law of diminishing returns ” and communication overhead discussed earlier are both contributing factors.
Adding people to a software project increases the total effort necessary in three ways: the work and disruption of repartitioning itself, training the new people, and added intercommunication.
— Frederick P. Brooks, Jr.
Additionally, some tasks cannot be broken down, and are said to have limited divisibility, thwarting teamwork. The colorful proverb, “it takes nine months to deliver a baby, no matter how many workers are assigned to the job,” illustrates the issue. These tasks are not accelerated by additional man–er, uhh… womanpower.
There are some cases where the law does not apply, e.g., when the tasks are highly parallelizable, such as in visual effects (VFX) production or other chores similar to “digging a ditch.” Well planned projects with high quality and good documentation are also less susceptible to Brooks’ Law than those that are mismanaged and chaotic. Additional mitigation strategies include:
Adding people earlier in the project reduces delays.
Focus on quality and roles
Reduction of communication overhead:
See also: Online Resources
Brooks’ Law Repealed?
Every project eventually reaches a point at which adding staff is counterproductive, but that point occurs later than Brooks’ law states and in limited circumstances that are easily identified and avoided.
— Steve McConnell, IEEE Software
In this piece , Steve McConnell makes a case that Brooks’ Law can be avoided through better planning and modern development techniques.
Let’s take a hike…
I make a mental note that we are out of toilet paper and need to stock up when we hit the next town. We turn the corner: a raging river is blocking our path. I feel a massive bout of diarrhea coming on...
— Michael Wolfe on Quora
Why are software development task estimations regularly off by a factor of two to three? A highly entertaining answer to the software estimation problem, using a journey from San Francisco to Los Angeles to illustrate.
9.2.3. More Legalese¶
Murphy's Law + Parkinson's Law + Hofstadter's law = Delays
— SixSigma on HN
Love it! Breaking it down:
- Murphy’s Law:
“Anything that can go wrong, will go wrong.”
- Parkinson’s Law:
“Work expands so as to fill the time available for its completion.” Also known as student syndrome.
The coup de grâce, from the famous geek-friendly book, Gödel, Escher, Bach: An Eternal Golden Braid :
- Hofstadter’s Law:
“It always takes longer than you expect, even when you take into account Hofstadter’s Law.”
The book Peopleware, by DeMarco and Lister (Ch.7) makes the case that Parkinson’s Law does not apply to software people if they are allowed to find satisfaction in their work and lack of bureaucracy.
Warning: Death March
The failure to properly analyze the business needs and determine what type of software was needed led to an ever increasing number of programmers. In the end a $300,000 custom online store cost $3,000,000 and ruined the entire division.
— thecodist

A metaphor from war , where prisoners are forcibly marched with intent to weaken or kill. While software projects never get that bad, it can be quite demoralizing to be forced to work on a doomed project “against your better judgment.”
Grueling hours are often required from workers to compensate for poor planning at the top levels.
9.2.4. Mitigation¶
If not for the courage of a fearless crew,
the Minnow would be lost… ♪
— Theme from Giligan's Island
So, what can we do to speed up a late project? The Priceonomics article mentioned previously has a few solutions :
Streamline internal process (e.g. have small edits get done by whoever proposed them rather than waiting on a second person).
Have short internal deadlines to keep a big buffer zone before the client deadline.
Schedule everything by timezone to remove long delays between collaborators.
Improve client notifications to help them respond faster.
They boil down to improving feedback loops through smaller milestones and improved communication during critical, blocking tasks. As mentioned here ad nauseum , bugs cost more to fix (in time and money) in the later stages than they do prevented in the first place. Steve McConnell observes in Rapid Development (Ch 4.), the second paragraph from Code Complete (Ch. 20):
Some projects try to save time by reducing the time spent on quality-assurance practices such as design and code reviews. Other projects—running late—try to make up for lost time by compressing the testing schedule, which is vulnerable to reduction because it’s usually the critical-path item at the end of the project. These are some of the worst decisions a person who wants to maximize development speed can make because higher quality (in the form of lower defect rates) and reduced development time go hand in hand.
The most obvious method of shortening a development schedule is to improve the quality of the product and decrease the amount of time spent debugging and reworking the software.
Warning: The Big Bang
…big projects always fail unless they are turned into carefully designed smaller projects which build upon one another; keep the core development team small and highly experienced, ensure that everyone knows what is going on at all times…
— thecodist
This piece at thecodist blog “Software Project Disaster Types: #6 The Big Bang” , illustrates the dangers of trying to “reinvent the world” in a single project, using Apple’s failed Copland OS project of the late 90’s as the main example. A follow-up piece discusses the failure of the first plan for Microsoft Vista. Ten thousand employees… shakes head.
9.3. Failure¶
In the simplest terms, an IT project usually fails when the cost of rework exceeds the value-added work that's been budgeted for.
— Robert Charette, IEEE Spectrum

Fig. 9.6 When your best just isn’t good enough… ¶
Regrettably, outright failure of software projects is not an uncommon occurrence, resulting in the destruction of billions of dollars a year. After studying dozens of techniques that have been shown to improve the probability of success in this book, you’ll surely be disappointed to find so many organizations (including those you’ll apply to after school) choose to ignore them. You’d be forgiven for thinking they appear determined to fail.
In 2013, The Standish Group released the latest version of their CHAOS report , a survey of fifty-thousand software projects over ten years, with somewhat dismal results. Of those projects:
39% Succeeded (on time, on budget, met requirements)
43% were Challenged (late, over budget, reduced features)
18% Failed (canceled or never used)
The number of favorable outcomes is on the upswing thankfully, as the techniques of success advance from research to common knowledge and spread across the industry. In comparison, their 2004 report found only 29% of surveyed projects successful. Certainly, there’s still room for improvement.
Size as a Major Factor
Also reported in the study was that the larger the project the more likely it was to fail. Accordingly, very large projects (> $10 million) were very likely to fail:
Large projects are twice as likely to be late, over budget, and missing critical features than small projects. A large project is more than 10 times more likely to fail outright, meaning it will be canceled or will not be used because it outlived its usefulness prior to implementation.
This finding agrees with those noted earlier under the Number of Milestones section. Projects with a greater number of sequential milestones will on average experience a greater number of delays. As these delays accumulate, larger projects suffer scheduling issues to a much higher degree.
9.3.1. Why Do Projects Fail?¶
The two biggest causes of project failure are poor estimation and unstable requirements (van Genuchten, 1991 et al.)
— Greg Wilson
The most common factors are listed below, courtesy IEEE Spectrum Magazine:
Dilbert: Designed to Fail
Unrealistic or unarticulated project goals
Badly defined system requirements
Stakeholder politics
Poor communication among customers, developers, and users
Unmanaged risks
Inaccurate estimates of needed resources
Sloppy development practices
Inability to handle the project’s complexity
Poor project management
Poor reporting of the project’s status
Commercial pressures
Use of immature technology
Many, if not most of these failures could have been prevented—they are the result of one or more of the “classic mistakes” in software project management that have been made over, and over, and over since the dawn of computing. Mistakes we’ll expand upon in the next section.
See also: Online Resources
And yet, failures, near-failures, and plain old bad software continue to plague us, while practices known to avert mistakes are shunned.
— Robert Charette
Why Software [Projects] Fail, IEEE Spectrum Magazine
A compelling article on a disappointing subject, the state of large IT projects.
HealthCare.gov:
20 Famous Software Disasters , by DevTopics
The 4 Top IT Project Management Disasters of All Time , by Tim Clark
Warning: The Train Wreck
Software Project Disaster Types: The Train Wreck, by thecodist.
The train wreck is similar to a death march, however rather than the rank and file being acutely aware of the coming disaster, in this instance they are more likely to have their heads buried in the sand blissfully unaware of impending doom. Possibly because management is withholding information, or inadvertently siloed it across divisions.
9.3.2. Classic Mistakes¶
When are companies going to stop wasting billions of dollars on failed projects? The vast majority of this waste is completely avoidable.
— Merrie/Andrew Barron, PMP, CSM, What is Project Management?
These classic mistakes , from Steve McConnell’s “Rapid Development,” are so common and repeated so often they’ve hit the Hall-of-Fame , woot! McConnell’s page linked above contains a full discussion of most items and should be read for reference.
From Rapid Development (Ch. 3):
Most of the mistakes have a seductive appeal. Do you need to rescue a project that’s behind schedule? Add more people! Do you want to reduce your schedule? Schedule more aggressively! Is one of your key contributors aggravating the rest of the team? Wait until the end of the project to fire him! Do you have a rush project to complete? Take whatever developers are available right now and get started as soon as possible!
People Mistakes:
Undermined motivation
Weak personnel
Uncontrolled problem employees
Heroics
Noisy, crowded offices
Friction between developers and customers
Unrealistic expectations
Lack of effective project sponsorship
Lack of stakeholder buy-in
Lack of user input
Politics placed over substance
Product Mistakes:
Requirements gold-plating
Developer gold-plating
Push me, pull me negotiation
Research-oriented development
Process Mistakes:
Overly optimistic schedules
Insufficient risk management
Contractor failure
Insufficient planning
Abandonment of planning under pressure
Wasted time during the fuzzy front end
Insufficient management controls
Premature or too frequent convergence
Omitting necessary tasks from estimates
Planning to catch up later
Code-like-hell programming
Technology Mistakes:
Silver-bullet syndrome
Overestimated savings from new tools or methods
Switching tools in the middle of a project
Lack of automated source control
New Classic Mistakes
Another decade of consulting by McConnell has identified a number of new classics :
Confusing estimates with targets
Excessive multi-tasking
Assuming global development has a negligible impact on total effort
Trusting the map more than the terrain
Outsourcing to reduce cost
Letting a team “go dark” (replaces the previous “lack of management controls”)
McConnell also recommends creating your own lists of “worst practices” to avoid on future projects. Keep them in mind when creating your own lessons-learned documentation.
Hint: Revisit This List, Padawan…
You should endeavor to make all-new, spectacular, never-seen-before mistakes.
— Jeff Atwood, co-founder StackExchange
Do you and your career a big favor and revisit this list occasionally, during each software project you develop or manage. If you can avoid the development tar pits listed above you’ll be far ahead of the game.
If you are experiencing one or more of these and not in a position of authority, you’ll probably want to bring the subject up with your PM and/or dev lead. Including a clip from an appropriate book on the subject such as those recommended in this chapter may help.
See also: Online Resources
101 Common Causes, another list of failures and their reasons.
9.3.3. Sabotage¶
You have enemies? Why, it is the story of every man who has done a great deed or created a new idea.
— Victor Hugo, "Villemain"
Another risk that might seem downright unbelievable is the intentional sabotage of a project. It’s fascinating (from afar, haha) that politics can get so bad that stakeholders will undermine a project (intentionally or through indifference) if it is perceived as threatening. Definitely something to be aware of—get those goals, requirements, and benefits aligned!
Stakeholders can champion your project and help drive success, but they can also be very effective saboteurs. Powerful stakeholders are much more likely to sabotage your project if they don't feel engaged.
— T. Morphy, stakeholdermap.com
Conversely, this blog post by Philip R. Diab examines the idea that sometimes a project may actually be destructive in some way and the attempted sabotage might have justification. It’s not hard to imagine a management team of sociopaths doing what they do—pushing a project for short-term gain of some sort (perhaps to collect a payday), that precipitates long-term damage to an organization—just check the financial news for examples. Interesting nonetheless.
Danger: Sabotage it Yourself!
…in Five Easy Steps , courtesy Value Hour:
Don’t work on requirements first.
Don’t let the developers talk to the people actually doing the jobs. ((boggle))
Don’t focus on the minimum viable product, or solicit feedback soon enough.
Don’t get the right people on board early enough to be effective.
9.3.4. Diagnosis and Aftermath¶
"Find and ask the doer", is a fantastic way to get to the root of a problem.
— Elizabeth Greene @ Quora
First, some background on the quote above. In 1986, an investigation was done by the Rogers Commission into the causes of the Space Shuttle Challenger disaster, which exploded shortly after takeoff one cold January morning. It was found, largely due to the notable work of the tenacious physicist Richard Feynman, that there was a great disconnect between the thinking of the management and engineering teams on the project. The engineers had warned about fatal problem(s) for years and had even attempted to stop the launch that particular morning, but were tragically overruled.
When you need to find out the true state of a project as it is sinking, or what really went wrong afterward, listen to managers and executives certainly, but the most accurate information will always be obtained from those “in the trenches” doing the work.
Find and ask the “doer.”
9.3.5. Schadenfreude ¶
Lest we start thinking that only the US government is capable of huge mistakes, consider the following examples.
Ninguém Merece

Here’s a doozy from Pertrobras, the Brazilian oil company. Apparently management found a great way to reduce costs on their new offshore oil drilling platform—by cutting expensive quality inspections and maintenance! Below are a few choice quotes from executives (translated) :
“Petrobras has established new global benchmarks for the generation of exceptional shareholder wealth through an aggressive and innovative program of cost cutting on its P36 production facility.”
“Conventional constraints have been successfully challenged and replaced with new paradigms appropriate to the globalized corporate market place.”
The savings were impressive indeed, right up until two explosions ripped through its starboard supports and the platform capsized a few days later. It turns out neglecting inspection and maintenance is not a long-term strategy for success.
Être Au Taquet
Far more serious than just a lack of professional competence was the utmost contempt for human dignity…
— Project Failures
A few choice figures:
|
|
You won’t know whether to laugh or cry after reading the following piece about a government “Project from Hell” and the discussion it generated. “Beatings will continue until morale improves”—an IT disaster with a French twist. 😂😢 Part II may be enjoyed here.
9.4. “No Silver Bullet” Revisited¶
So we come back to fundamentals.
Complexity is the business we are in, and complexity is what limits us.
— Fred Brooks, The Mythical Man-Month, 2nd Ed. (Ch. 17)
We’ve finally arrived at the end of Part I of this book (Foundations) and have undoubtedly learned a lot; there is no end to it in this business. Hopefully, it’s obvious by now that there are no magic breakthroughs on the horizon to make ambitious projects substantially easier to complete than they are now—only hard work ahead.
The famous 1968(!) demo by Douglas Englebart at SRI, demonstrating much of modern computing.
Hardware and tools will keep up their progress of course,
getting out of our way and assisting as much as possible.
But the big,
fundamental problems of complexity are as intractable now as they ever were,
especially as we aim higher,
standing on the
shoulders of giants
that came before us.
The NeverEnding Story…
All this has happened before, and it will all happen again.
— Peter Pan (1953)

The quote above is somewhat comforting yet a bit disturbing, no? From great ideas forgotten to greater disasters replicated, software history appears destined to repeat itself—everything old is new again. Is there an alternative?
In your career, you’ll find it helpful to step back every five years or so to read, reread, and learn from those that have gone before and lived to tell their tale. With help, you too can evade the software tar pits , Mobiuses (Mobi’i?), and “Giligan’s island(s)” of history with a combination of study and experience.
Accordingly,
the following parts of the book strive to accelerate you to
escape velocity .
If you’ve made it this far
“good on ya, mate” ,
as they say
down under .
Thanks for reading.
Hint: But Wait—There’s MOAR!
Part II: Nuts and Bolts, and Part III on Productivity may be found below.
\(`0´)/
Yes, this is a button. ;-)
Buy the full book at Gumroad:
Buy at: Amazon Store for Kindle, iOS, and Android, Mac, and Windows. (Has a few formatting limitations.)
Remember, the book is still in progress and currently half price. A purchase now (at the lower price) will entitle you to the full book when it is finished.
TL;DR
Most of the organizational challenges your project is facing today were recognized, managed, and written about by the 1970s, but sadly many organizations can’t be bothered to look up the solutions.
Risks must be identified, classified, and managed for a project to succeed.
Don’t let “scope creep” doom your project, it will try.
“The second is the most dangerous system a person ever designs; the general tendency is to over-design it.”
“The single worst strategic mistake that any software company can make: rewriting the code from scratch.”
Keep projects small to improve their chance at success; avoid “reinventing the world.”
The planning fallacy, optimism bias, self-serving bias, and the uncertainty of innovation all contribute to underestimates in scheduling.
Tasks can never be done faster than immediately, but potentially may take up to “forever,” therefore those tasks that finish ahead of schedule cannot fully balance out those running behind.
Brooks’ Law: “adding ‘manpower’ to a late project makes it later.”
“Murphy’s Law + Parkinson’s Law + Hofstadter’s law = Delays”
Double estimates, triple if there are numerous dependent steps in a project, or if the team is working in an environment of interruption.
Most of the mistakes made in project management have been well known for decades. Avoid these “classic mistakes” in favor of the unique.
Revisit the list of “classic mistakes” yearly to confirm you’re not committing them.
“It’s unlikely that everyone you encounter will be an ally.” Keep them close.
“‘Find and ask the doer’, is a fantastic way to get to the root of a problem.”